本文共 6195 字,大约阅读时间需要 20 分钟。
分析一次SQL并行执行的产生过程
1、并行引起的灾祸
一大早,某网省兄弟告诉我,数据库会话执行的SQL开启了并行,导致负载很高,会话也高,查了半天,没找到具体原因,也不知道该如何解决?
对于他的问题,我直接回应了:这还不清楚吗?常见原因无非有以下两个:
第一:对象开启了并行(包括索引和表)
第二:SQL语句里面使用了PARALLEL的HINTS
现场兄弟说,都查了并没有上面的情况,听到他的回答,我首先对他查询的方式持怀疑态度的,没有设置并行度,也没有加HINTS,执行的SQL怎么会并行执行呢?带着这个疑问,我叫现场兄弟把查询结果一一截图给我,如下(文中案例都是事后补充):
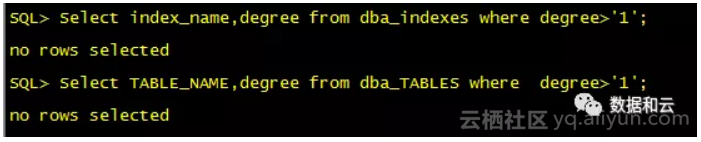
看到结果后我一时也有点摸不着头脑,怎么回事?遇到问题我总是告诉自己要冷静,不急。
2、层层推进,分析问题
是不是什么参数控制了?
SQL> show parameter parallel
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fast_start_parallel_rollback string LOW
parallel_adaptive_multi_user boolean TRUE
parallel_automatic_tuning boolean FALSE
parallel_degree_limit string CPU
parallel_degree_policy string MANUAL
parallel_execution_message_size integer 16384
parallel_force_local boolean FALSE
parallel_instance_group string
parallel_io_cap_enabled boolean FALSE
parallel_max_servers integer 320
parallel_min_percent integer 0
parallel_min_servers integer 0
parallel_min_time_threshold string AUTO
parallel_server boolean FALSE
parallel_server_instances integer 1
parallel_servers_target integer 128
parallel_threads_per_cpu integer 2
recovery_parallelism integer 0
没有发现可疑参数。
至此,表面排查的结果已经解决不了这个问题了,于是我让现场找了一条正在并行的SQL ,手动执行,并收集一个10053事件trace,看看是否能有新发现。脚本如下

很快现场提供了TRACE FILE文件给我,我优先看参数列表。
这时,我发现一个可疑的参数:parallel_query_default_dop = 16

找到mos上关于该参数的相关信息,是一个默认并行度的参数,该参数值的算法如下:
DEFAULT DOP = cpu_count * parallel_threads_per_cpu* cluster_database_instances
我立刻问现场同事,执行的SQL在活动会话中体现的是不是16个并行进程。现场同事答复我,观察到的基本就是。至此问题明朗起来了,执行的SQL使用了默认并行度执行,受参数parallel_query_default_dop控制。既然是默认的并行度,那也应该需要设置(如果不设置,默认是1)。于是我把前期的查询验证对象并行度是否开启的SQL改造了下,具体如下(文中案例都是事后补充)
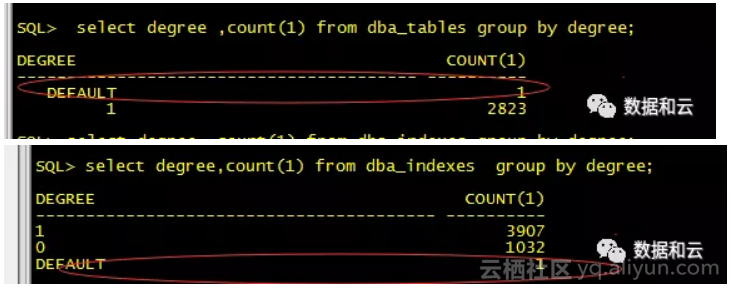
查询结果截图发出来,我就开心了,这里明显有一个设置了并行度为DEFAULT(如果我们不设置就是1)的表和索引。然后确认了他们正是正在运行的sql中的对象。
3、问题解决
既然设置了默认并行度,那么只需要取消默认并行度即可,即执行如下SQL
--针对表
alter table table_name noparalle;
--针对索引
Alter index index_name noparallel;
于是我叫现场把对象并行度修改为1,再次执行该SQL,发现并行消失了,数据库恢复了正常。
问题虽然解决了,但还有一个疑问没有解开,什么情况下会设置的并行度为DEFUALT呢?正常创建索引和表都是1。
4、如何设置并行度为default
通过实践发现如下2种方式可以实现并行度设置为DEFAULT。
1、创建表的时候指定:
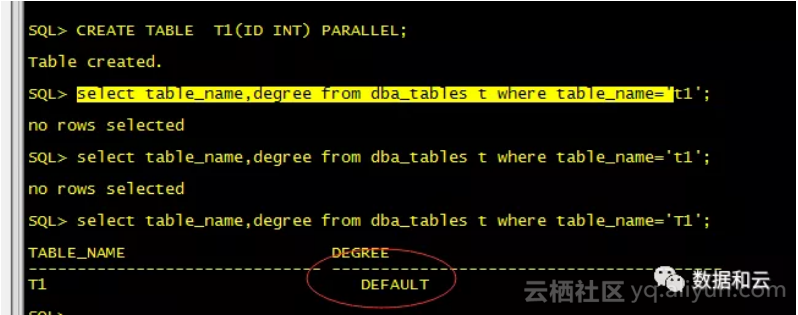
2、创建表之后可以修改
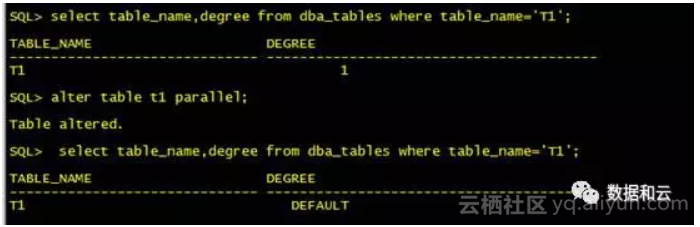
小结:该问题解决第一个是思路 ,第二个是基本功要扎实。
DB升级之后,DBLINK引起执行计划异常分析
背景如下:某网省采集中间库从10.2.0.4升级到11.2.0.4(备注升级不是在老的机器上面直接升级,而是在新机器上面采用安装迁移的方式)
升级完第二天现场找到我,说以前同步档案数据的接口功能目前都运行非常慢(数据接口同步的方式采用的DBLINK),有时甚至无法正常运行完,影响档案资料的同步,看来已经很严重了。
关键字:DB升级从10G升级到11G
我以前遇到过相关案例,觉得可能是升级带来的执行计划变化引起的。于是告知现场尝试修改优化器参数即optimizer_features_enable改成10.2.0.4,可以在线改,立刻生效,脚本如下:
alter system set optimizer_features_enable='10.2.0.4' scope=both;
修改完成后,重新在执行同步档案资料接口的任务看是否正常。
现场经过一番测试之后,问题没有解决,看来老的经验无法解决该问题。
好,接下来我们做了以下模拟测试:
该SQL的文本如下:
INSERT INTO EPCT.C_CUST_ADDR@EPEXDB
(CUST_ID,CUST_ADDR,PROVINCE_CODE,CITY_CODE,COUNTY_CODE,STREET_CODE,VILLAGE_CODE,ROAD_CODE,COMMUNITY_CODE,PLATE_NO,TYPE_CODE,POSTALCODE,CA_ID,APP_NO)SELECT A2.CUST_ID,A2.CUST_ADDR,A2.PROVINCE_CODE,A2.CITY_CODE,A2.COUNTY_CODE,A2.STREET_CODE,A2.VILLAGE_CODE,A2.ROAD_CODE,A2.COMMUNITY_CODE,A2.PLATE_NO,A2.TYPE_CODE,A2.POSTALCODE,A2.CA_ID,''FROM SGPM.C_CUST_ADDR A2WHERE A2.CUST_ID=ANY(SELECTA3.CUST_IDFROM SGPM.C_CONS A5,SGPM.R_CP_CONS_RELA A4,SGPM.C_CUST A3WHERE A4.CONS_ID=A5.CONS_IDAND A4.CP_NO=:B1ANDA5.CUST_ID=A3.CUST_ID);
可以看到是用到DBLINK从A数据库到B数据库的插入语句,这个SQL发起端在A数据库,也就是程序部署在A数据库中,而该SQL实际执行端在B数据库。虽然是往B数据库插入数据,但是会派生一个查询SQL到A数据库取数。
针对INSERT INTO remote_table@dblink select * from local_table这种SQL执行端都会在远端,不是本地,无法使用HINTS driving_site指定执行端。
2、然后会在A数据库确认一下是否派生一个SQL,并且找到该SQLID
3、现场提供SQLID之后,我们可以获取该sql执行的相关信息:
select *from table(dbms_xplan.display_cursor('1ar4us01aj0hu',null,'ADVANCED'));
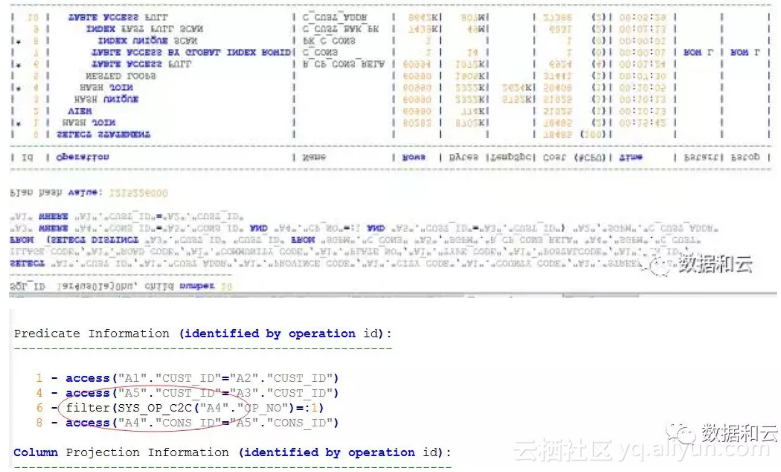
红框里出现的字样引起了我的注意,眼尖的DBA应该很快会发现其中的猫腻。
对的,这里调用了一个内部函数。这个函数的说明如下:
The internal Oracle function SYS_OP_C2C performs conversion
from one character set to another character set C(haracterSet)2C(haracterSet).
字符集之间的转换。OK ,看到这里我问现场,新旧两套B数据库中字符集是什么? A数据库字符集又是什么?
现场答复如下:
老的B数据库字符集是utf-8
新的B数据库字符集是zhs16gbk
而A数据库字符集是utf-8
这个也就说明了,迁移到新采集中间库之后性能急剧下降的原因找到了。
那么解决方式有如下2种方式:
第一修改字符集,保证源目标字符集一致。
第二创建函数索引。
域索引导致提交报告的展开讨论
域索引导致提交报错
最近处理了一个网省的问题,现场反馈提交报错 ,报错如下:
COMMIT;
ERROR at line 1:
ORA-00604: error occurred at recursive SQL level 1
ORA-20000: Oracle Text error:
DRG-50610: internal error: drexdsync
DRG-50857: oracle error in drekrtd (reselect rowid row locator)
ORA-00942: table or view does not exist
ORA-06512: at "CTXSYS.SYNCRN", line 1
ORA-06512: at line 1
看到这个错误,我们获取到如下信息
1、这个是关于域索引的报错
2、这个是递归SQL导致的报错
3、这个是报表或者视图不存在(最大可能是权限 或者可能就是真不存在)
见到这个错误,首先找现场核实下权限问题,包括操作用户的权限
核查结果并没有异常。
进一步分析:
1、查询域索引信息
Select * from ctxsys.ctx_indexes
2、创建一个域索引会自动创建属性为BASIC_STORAGE的四个二级表对象和一个索引对象出来
BASIC_STORAGE has the following attributes:i_table_clause Parameter clause for dr$$I table creation.The I table is the index data table.k_table_clause Parameter clause for dr$ $K table creation.The K table is the keymap table.r_table_clause Parameter clause for dr$ $R table creation.The R table is the rowid table.n_table_clause Parameter clause for dr$ $N table creation.The N table is the negative list table.i_index_clause Parameter clause for dr$ $X index creation.
大家可以在自己的环境中使用如下SQL查询
Select owner,object_name,object_type,secondary,statusfrom dba_objectswhere owner ='SGPM'and object_name like 'DR$INDEX_NAME$%' --INDEX_NAME修改为你实际的名称
现场查询结果为空,说明域索引已经不存在了,从而导致提交报错,也就是递归执行域索引的SQL报错。
问题定位到,解决问题的办法很容易:
重建域索引即可。
我这里给出的例子指出了域索引的实际存储表空间位置,目的就是可控,如果不指定就是创建用户所在默认的表空间。
begin
--创建词法分析--ctx_ddl.create_preference ('chinese_lexer', 'chinese_lexer');--存储参数ctx_ddl.create_preference('t1_stor','BASIC_STORAGE');ctx_ddl.set_attribute('t1_stor','I_TABLE_CLAUSE','tablespace TEST');ctx_ddl.set_attribute('t1_stor','I_INDEX_CLAUSE','tablespace TEST');ctx_ddl.set_attribute('t1_stor','K_TABLE_CLAUSE','tablespace TEST');ctx_ddl.set_attribute('t1_stor','R_TABLE_CLAUSE','tablespace TEST');ctx_ddl.set_attribute('t1_stor','N_TABLE_CLAUSE','tablespace TEST');end;--创建域索引 指定storage参数和lexer词法分析器参数create index idx1_t1 on t1(object_name) indextype is ctxsys.context parameters ('lexer chinese_lexer storage t1_stor');--同步域索引数据:(该操作有风险业务低估操作)查询确认域索引是否需要同步select u.username, i.idx_namefrom ctxsys.dr$index i, dba_users uwhere u.user_id=i.idx_owner#and idx_id in (select pnd_cid from ctxsys.dr$pending);exec ctx_ddl.sync_index('IDX1_T1');--优化域索引数据(该操作有风险业务低估操作)exec ctx_ddl.optimize_index ('IDX1_T1', 'full'); 转载地址:http://tgxal.baihongyu.com/